
I once had to solve a problem of such complexity, no one knew even whether it could be solved. A program was needed to process raw telemetry data collected by sensors and produce a model of the physical environment from that data for a particular military purpose. Others who came before me attempted to design functions to transform this raw sensor data using Fourier transforms, radial geometric mapping, applicable laws of classical mechanics, and nonlinear differential equations. None of this resulted in much success. I knew I wouldn’t have the time to understand what had already been attempted, much less find out whether further work should be done to improve it. I also didn’t have a PhD in math. What I did know, was that a lot of real world telemetry data had been collected and analyzed by humans as training examples, so that for many sets of input data, the desired output models were known.
The only thing that was missing was the algorithm. Thus the challenge was to code the algorithm to automatically produce a useful output model when future input sets would be received by the sensors. I had access to massive compute resources (comparable to a gaming console’s GPUs today), so I decided the best thing to do was to go back to the drawing board and approach the problem from an entirely new angle, using the algorithm that predates human intelligence to produce all the living complexity in Nature-- Darwinian evolution by natural selection.

Could you evolve a mousetrap??
Since that time, I have always been fascinated by software evolution-- understanding where it should be applied practically, its limitations, and what can be done with what it can produce. In fact, I even reached out to Dr. Michael Behe, author of “Darwin’s Black Box” and other Intelligent Design theorists like Dr. Bill Dembski , trying to learn about, formalize, and test their objections in my simulated worlds. I never did get the mathematical model of irreducible complexity or even one describing a lowly mousetrap I requested, but the idea is that there exists some class of algorithms that cannot possibly be discovered by evolution directed by natural selection. I remain at once skeptical and intrigued.
(Neo) Darwinian Evolution
Most people are familiar with the algorithm of evolution by natural selection. Given a large population of organisms, some will be better adapted to their environment than others. The most well-adapted of these produce offspring whose genetics will be similar to their own. Genetic mutations will occur at random, almost always detrimental or fatal, but only very rarely result in individuals with far superior adaptive characteristics. This cycle repeats over many thousands of generations.
For use in software, these steps are modified:
Generate a large number of random programs
Execute each program and collect its output
Assign each program a fitness score based on the quality of this output
Select specimens from the population with a probability of “reproducing” based on their fitness score to be parents of the next generation
Generate a new population by combining the code of parent programs
Occasionally select a specimen and alter its program slightly at random (mutation)
Repeat the process for many generations
The concepts are what are important-- simulated evolution is an attempt to identify and make use of the most effective principles of biological evolution, and (mercifully) need only replicate only a few of these many complex characteristics of real biological organism including metabolism, sex, amino acids, protein synthesis and many, many others..
Generating and Executing Random Programs
Almost all the literature on genetic or evolutionary algorithms and programming assume a binary tree program structure-- an operator node with two operands as child nodes, but this approach has some undesirable characteristics and limitations which probably is why less work has been done studying evolutionary programming than artificial neural networks in the field of AI. Real world complex programs are not a binary operation, and it’s hard to see how much code reuse can be exploited by evolution using this approach.
I prefer to produce linear/imperative programs instead (e.g. a series of assembly language instructions) because they will be simpler to decompile, analyze and optimize manually. I also believe they offer better code reuse potential in the search space. Imagine a randomly generated binary executable. If you are lucky, it probably won’t do anything. Unlucky, and it will go into an infinite loop, attempt division by zero, destroy and corrupt files, allocate 100% of application memory, etc. To prevent this, randomly generated programs must execute safely within a virtual machine especially designed to safely load, execute and monitor the most pathological programs.
So the first thing I did, was write a virtual machine designed never to crash. This VM can terminate poorly behaved programs by limiting the raw number of instructions they can execute. It handles all attempts to execute invalid operations, invalid operands and bad pointers. It can provide a finite amount of memory to the program and define the I/O channels. It ignores or rewrites instructions that would otherwise cause a program to crash. In short, every program run on this VM must execute “successfully.”
It must be the virtual machine’s responsibility to terminate a program, never assuming that any program is designed to self-terminate because in fact none of the programs it will execute are designed at all. The programs must execute in a thread-safe, parallel manner. The population size can be determined empirically and held more or less constant from generation to generation based on the compute resources available. In this sense, the VM includes a rudimentary operating system that monitors and kills misbehaving programs, and provides access to memory and I/O. Separate from the VM is an EvolutionManager responsible for creating populations (reproduction and mutation), scheduling them for executing, analyzing the results.
Fitness Function
A program is a sequence of random bytes submitted to the virtual machine for execution. The first generation of programs will be absolutely terrible. Few or none will even read any input, produce any output or perform any valid or useful operations. Yet, no matter how pathetic or pathological, each program will have a fitness score computed by a fitness function. It is impossible to overstate the importance of the fitness function or how difficult it is to design a good one.
For example, suppose you are trying to evolve a sorting algorithm. There is exactly one correct output for a given list of inputs. Certainly there needs to be a fitness score between unsorted (say, 0.0) and sorted (1.0), otherwise you will never evolve an algorithm. To implement this, you might count the length of the longest sorted subsequence present in the output. You might “add points” for reading the input, outputting the correct number of items, outputting only numbers present in the input list, etc.
To do this requires support from the VM to allow the fitness function to obtain detailed information about runtime characteristics of programs. Most of the work is in designing a useful fitness function. (In case you are interested, evolution almost always produces the insertion sort).
Creating the Next Generation
After all programs execute and are scored, a sum of all the scores is computed. Each program’s fitness score is some fraction of this sum. This fraction represents the chance that the organism will be selected to be one of the parents of a new program in the next generation. For example, programs that score 0 will have NO chance, and the best performing programs will have the highest probabilities. All we need to do is repeatedly generate a number between 0 and the total sum of scores. Then we iterate over the array of programs, keeping a running total of the fitness scores encountered until the random number is reached-- that selects a parent.
Following Nature, we will select two parents and mate them. This can be done by applying the crossover genetic operator on the selected parent programs because the programs are binary data:
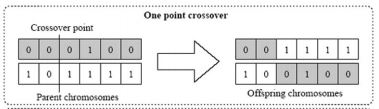
A randomly chosen crossover point ranging in value from 0 to the length of the shortest program is used and the crossover is performed so that the child program has part of the code of each parent. Before the program is added to the new generation, there is a very small chance that a mutation should occur. Again, following the example of Nature, a mutation can mean inserting, changing, or deleting one or more bytes of the program. Mutations are essential to avoiding the situation where the evolutionary process discovers a local maxima over the search space. This means that no further improvements to programs can be discovered without introducing some radical alteration.
Intelligently Designed Evolution
Evolution as is supposed to have occurred in Nature to produce all the living complexity in the world is thought to require time on the order of billions of years. Well, since I don’t have that kind of time, there’s no reason why that in an artificial world, with artificial organisms having artificial genomes, I can’t introduce principles of evolution that we do not observe in Nature-- that is, non-Darwinian forms of evolution.
One of the most well-known kinds of non-Darwinian evolution is Lamarckian Evolution which proposes that organisms tend to pass on those traits they make use of.

The virtual machine can keep track of the number of times each program instruction was executed. Then, instead of using a simple crossover combination, frequently executed instructions can have a higher chance of being copied. According to Neo-Darwinism, the way environmental conditions can affect future generations is through epigenetics.
When you're familiar with Evolutionary Programming, you'll quickly realize that evolution will always cheat if you let it. Consider the sorting algorithm example once again. Let’s say the environment always consists of the following inputs { 421, -4, 612 0, 1, -8, 13 }. Then evolution will invariably produce a produce a program like this:
output -8
output -4
output 0
output 1
output 13
output 421
output 612
That's right. The best program simply hardcoded the output. You see, it’s much simpler to produce the highest scoring sequence than to look at the inputs and actually sort them, so the winning program will never even look at the input values. To prevent this from happening, you need to either vary the inputs, at least for every new generation.
Also, if you always present the population with, say, six input values, or only non-negative integers less than 1,000, the sorting algorithm you will evolve will be capable of sorting exactly six integers from 0..1000. This is just the way evolution works. This may be fine for the problem you are trying to solve, but keep in mind that the highest scoring programs will be adapted to none other than the environmental conditions (i.e. input sets) they are presented with.
The Advantages
There are some "problems" for which there is no solution. For example, determine a betting method that always wins at the game of roulette. Evolution will tell you that by producing a program that never bets any money.
When (or rather, if) evolution produces a program that consistently scores well, we can take the program and disassemble it. In fact, from this you should be able to produce human-readable code in a language like C. This code can be studied to determine why the program works, optimized, cleaned up and refactored. It has the potential to be readily integrated into existing systems without reference to the virtual machine.
This kind of result is impossible with artificial neural networks. If you have a problem that is a good candidate for AI and you want to understand the solution, the evolutionary programming might be an excellent approach to consider.
